






Pricing model
Developer toolsA new product offers serverless GPU inference for ML models, eliminating the need for managing servers and providing a cost-effective and efficient solution for data processing needs.
Description
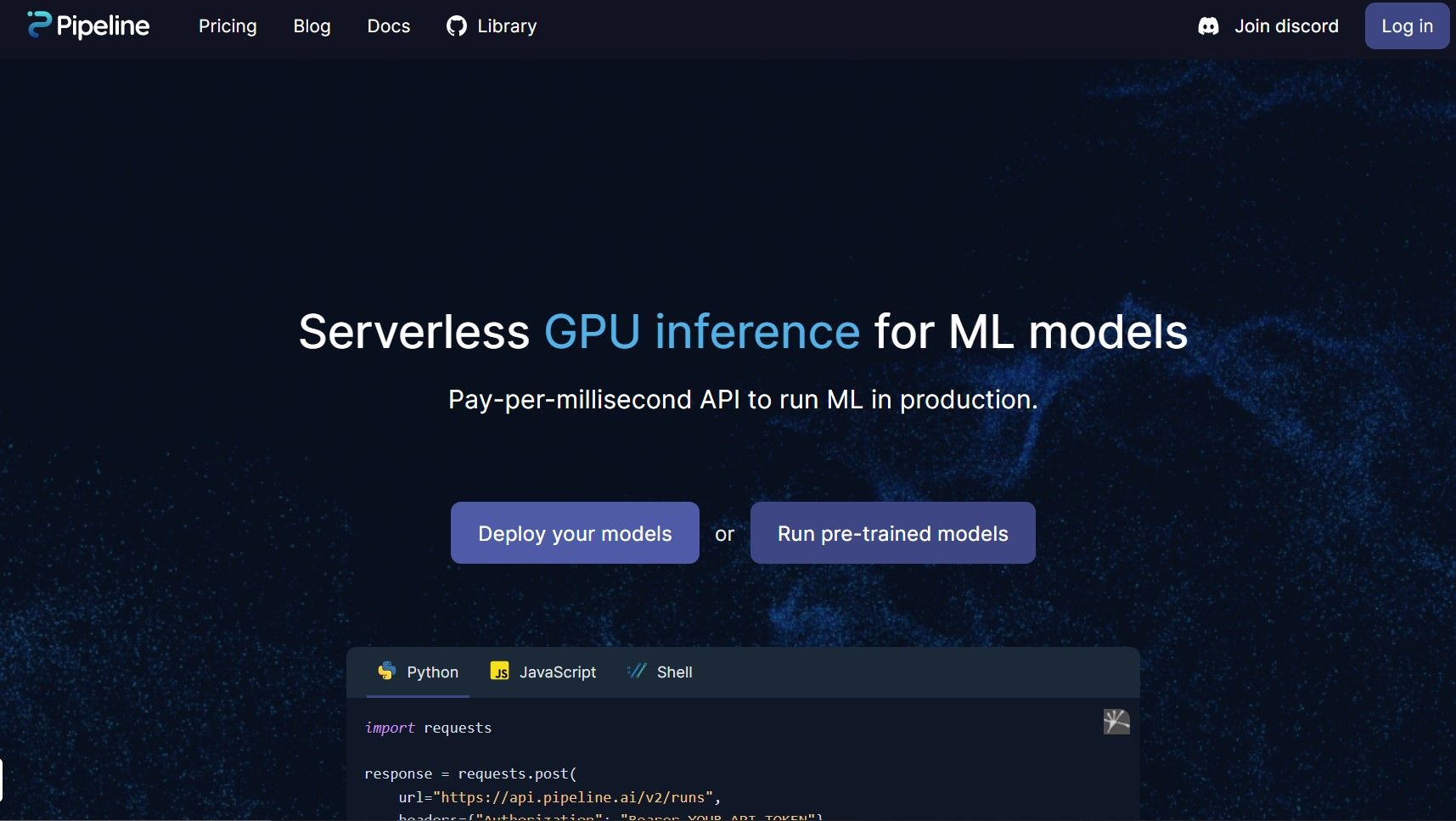
Introducing our groundbreaking product that enables serverless GPU inference for Machine Learning (ML) models, taking your data processing capabilities to new heights! Our modern technology is here to help you leverage the cutting-edge power of GPUs, while eliminating the need for managing servers or worrying about infrastructure.
With our platform, you can deploy your ML models easily and efficiently without the hassle of provisioning, maintenance, and scalability headaches. Our product is geared towards those who want hassle-free and cost-effective solutions for Machine Learning inference.
Our pay-per-millisecond API lets you run your ML models in production, providing a reliable and scalable solution for all your data processing needs. With our product, you can focus on building excellent products while leaving the server management to us.
Say goodbye to long wait times, excessive infrastructure costs, and never-ending server maintenance tasks. Our product offers a comprehensive, affordable, and efficient way to leverage Machine Learning inference at scale. Get started with our serverless GPU inference solution today!
Pipeline AI reviews
Be the first to review “Pipeline AI”
Pipeline AI alternatives
-
Semantic Kernel is an AI-powered tool that allows developers to enhance their applications using advanced features such as prompt chaining, recursive ... read more
-
NocodeBooth is a web-based app template that allows users to easily launch their own AI Image Generation Platform, without requiring much technical ex... read more
-
Appicons AI is an AI-powered icon generator that allows users to create professional and attractive icons with a 3-step process and flexible pricing, ... read more
-
Amazon Bedrock is an AI platform that helps users build and scale generative AI applications. It provides a wide range of foundation models built by l... read more

There are no reviews yet.